
서론
넷플릭스가 어떻게 “실험 설계 - 데이터 수집 - 피쳐 생성 - 모델 학습 - 검증 - 테스트 - 온라인 배포”의 반복을 빠르게 수행할 수 있는 시스템을 설계했는지, 특히 과거의 컨텍스트가 필요한 오프라인 실험과 현재의 컨텍스트를 필요로하는 온라인 시스템에서의 피처 계산의 간극을 없애서 매번 새로운 시스템을 개발해야 했던 시간을 줄였는지에 대한 이야기입니다.
또한 피쳐를 어떻게 생성하고 사용하는지 즉, 미리 저장하는지 혹은 매번 새로 생성하는지에 대한 내용, 피쳐 인코더와 모델에 대한 내용, 실험 반복(Iteration)에 대한 내용, 어떻게 피쳐 인코더를 통합적으로 관리하는가를 담고 있어 많은 것을 배울 수 있습니다.
이 글은 Distributed Time Travel for Feature Generation의 글을 번역 및 요약했습니다.
넷플릭스는 Data-driven 알고리즘을 이용하여 유저들의 개인화를 진행합니다. 넷플릭스의 목표는 유저들이 자리에 앉자마자 최고의 컨텐츠가 자동으로 재생되는 것입니다. 여전히 갈 길은 멀지만, 이것은 서비스의 전반에 걸쳐있는 알고리즘을 개선하기 위한 비전의 토대가 됩니다.
넷플릭스에서는 알고리즘을 개선하기 위해서 두 단계의 접근법을 따릅니다.
- 과거의 데이터를 사용하여 오프라인 실험을 진행하기
- 온라인 A/B 테스트를 통해 현실의 핵심 지표들을 측정하기
머신러닝 모델을 개선하기 위해서 다양한 방법들이 있겠지만 가장 중요한 것은 더 좋은 인풋 데이터를 사용하는 것입니다. 모델은 좋은 데이터가 있어야만 좋은 결과를 낼 수 있습니다. 그래서 새로운 인풋을 실험하는 데에 많은 시간을 보냅니다. 대부분의 모델은 입력이 피쳐 벡터로 알려진 숫자 벡터로 표현됩니다. 즉 우리는 ‘멤버 프로필’, ‘비디오’, ‘국가’ 등과 같은 인풋 엔티티와 그와 관련된 구조화된 데이터가 피쳐 벡터로 나타내어지길 원하는데 이러한 것을 Transformation Feature Generation이라 부르고 이것은 학습을 위한 데이터의 중심에 있습니다. 이때 피쳐라는 용어를 광범위하게 사용하는데 단순한 지표일 수도 있고 Matrix Factorization과 같은 모델에서는 전체 모델을 가질 수도 있기 때문입니다.
이제 Apache Spark를 사용하여 만든 Time Machine을 통해 어떻게 오프라인 실험에서 온라인 A/B 테스트로 매끄럽게 진행하는지를 알아봅니다.
타임머신을 만든 이유
피쳐를 생성하기 위해 사용해 왔던 다양한 접근법이 있습니다. 한 가지 방법은 피쳐를 S3에 저장하고 Hive를 통해 접근하는 것입니다. 이 방법은 Exploratory Analysis에는 적합하지만 몇 가지 문제점 또한 존재합니다. 첫째는 A/B 테스트를 위해서는 온라인에서 피쳐를 생성해야 한다는 점입니다. 우리는 추천의 Freshness와 Responsiveness가 유저의 경험에 아주 중요하다는 것을 알고 있습니다. 그 때문에 Hive가 아닌 온라인에서 피쳐를 다시 생성해야 합니다. 오프라인과 온라인에서 데이터 소스의 불일치는 모델의 결과물에 아주 큰 영향을 끼치기 때문에 두 가지 구현을 정확히 일치시키는 것은 매우 어렵습니다. 또한 우리의 모든 데이터, 추천이 오프라인에서 제공할 수 있는 것은 아닙니다. Sprase-to-dense conversion을 수행하기 때문에 아주 많은 데이터 볼륨이 생성되기 때문입니다.
다른 방법은 피처를 모델이 사용될 온라인에서 생성하는 것입니다. 이러한 방법은 오프라인과 온라인의 간극을 줄이고 A/B 테스트로의 전환을 쉽게 수행할 수 있게 합니다. 그러나 각 아이디어를 위한 새로운 피쳐를 프로덕션 환경에 배포하고 피쳐가 유유믜한지에 대해 오랜 시간 동안 기다려야 함을 의미합니다. 이것은 실험의 반복 사이클을 느리게 하고 모든 피쳐가 온라인에서 사용 가능해야 한다는 전제가 있습니다. 또한, 데이터들을 서빙하고 이것들이 가치가 있는지 판단할 새로운 시스템을 만들어야 합니다. 한편으로는, Label Data에 기초한 학습을 위해서는 추가되는 멤버나 요청들(requests)의 피쳐를 실제로 필요한 양보다 더 많이 계산하여야 합니다.
우리는 시청기록과 같이 타임스탬프 이후의 데이터를 필터링 할 수 있는 호출하는 기능을 시도해봤습니다. 그러나 이러한 방법에서는 서비스가 모든 과거의 이벤트를 기록해야 했고 모든 서비스에서 사용할 수는 없었습니다. 또한 피처 생성 시 마다 매번 온라인서비스에 부하를 주었습니다.
위의 접근법들을 통해 우리는 시간이 굉장히 중요하단 것을 알았고 여러 가지 방법들의 장점만을 취하고 싶었습니다. 따라서 우리의 목표를 아래와 같이 정리했습니다.
- 새로운 아이디어에서 모델링, A/B 테스트까지의 반복을 빠르게 한다.
- 온라인 마이크로서비스에 부하를 주지 않고 데이터를 사용한다.
- 모델을 위한 데이터를 특정 시점에 제시간에 나타나게 한다.
- 수많은 리서처들이 사용할 수 있도록 데이터 스케일링을 쉽게 수행 한다.
- Notebook과 같은 상호작용 환경에서도 잘 작동하고 학습을 위한 배치작업에서도 잘 작동한다.
- 피쳐 코드는 한 번만 작성하여 두 가지 구현이 일치하는지 판단하는 시간을 줄인다.
- 모순이 생기지 않도록 한다. 즉, Label이 Feature로 사용되지 않도록 한다.
타임머신은 어떻게 만드는가?
온라인 서비스의 스냅샷을 남기기 위해 타임머신 내에 필요한 컴포넌트들은 다음과 같습니다.
- 스냅샷을 위한 컨텍스트 선택
- 선택된 컨텍스트를 위한 마이크로 서비스의 데이터 스냅샷
- 과거 시간 좌표의 데이터를 서빙하기 위한 API
컨텍스트 선택
모든 컨텍스트 데이터(멤버 프로필, 디바이스, 시간)를 전부 기록하는 것은 효율적이지 않습니다. 대신에 컨텍스트 샘플을 주기적으로 선택합니다. 또한 어떠한 알고리즘들은 시청 패턴, 디바이스, 서비스 사용 시간과 같은 특성에 기반을 둔 Stratified 샘플이 필요로 합니다. 이러한 처리를 위해 Spark SQL을 이용해서 Hive로부터 실험에 적절한 컨텍스트 샘플을 선택합니다. 실험에 걸쳐 설정된 컨텍스트 샘플을 병합하고 이것을 S3에 대응되는 실험 식별자와 함께 유지합니다.
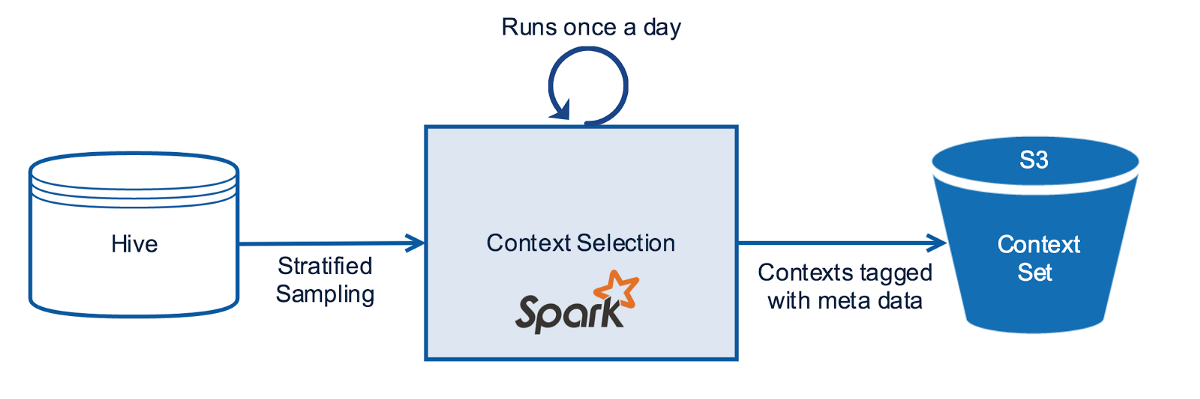
데이터 스냅샷
다음은 수 백개의 마이크로 서비스에서 데이터를 가져와야 합니다. 시청 기록, 마이 리스트, 예상 별점과 같이 다양한 서비스에서 오는 데이터들은 피쳐를 위한 인풋으로 사용됩니다.
우리는 Eureka, Hystrix, Archaius와 같은 넷플릭스 컴포넌트들을 사용하여 데이터를 가져옵니다. 그러나 몇몇 데이터를 가져오는 클라이언트들은 데이터를 통째로 가져오기 때문에 높은 메모리 사용량을 가지고 시작하는 시간도 깁니다. 또한 Spark Jobs를 실행하기 위한 Uber jar의 생성 요구사항은 넷플릭스 라이브러리와 런타임 호환성 이슈를 발생시켜 스파크는 이러한 작업에 적합하지 않다고 판단하였습니다. 이러한 문제를 완화하기 위해 Prana를 데이터 프록시로 이용하는데 이는 Spark JVM 위에서도 실행할 수 있었습니다.
내부적으로 컨텍스트들의 데이터를 가져오는 Prana 호출을 Spark는 병렬화합니다. 그리고 Thrift를 바이너리 통신 프로토콜로 사용합니다. 스냅샷 데이터는 Parquet를 이용하여 시간과 공간을 절약하고 Column-oriented 바이너리 포맷으로 압축해서 S3에 저장합니다. 그리고 Cassandra에 S3 데이터의 위치를 저장합니다.
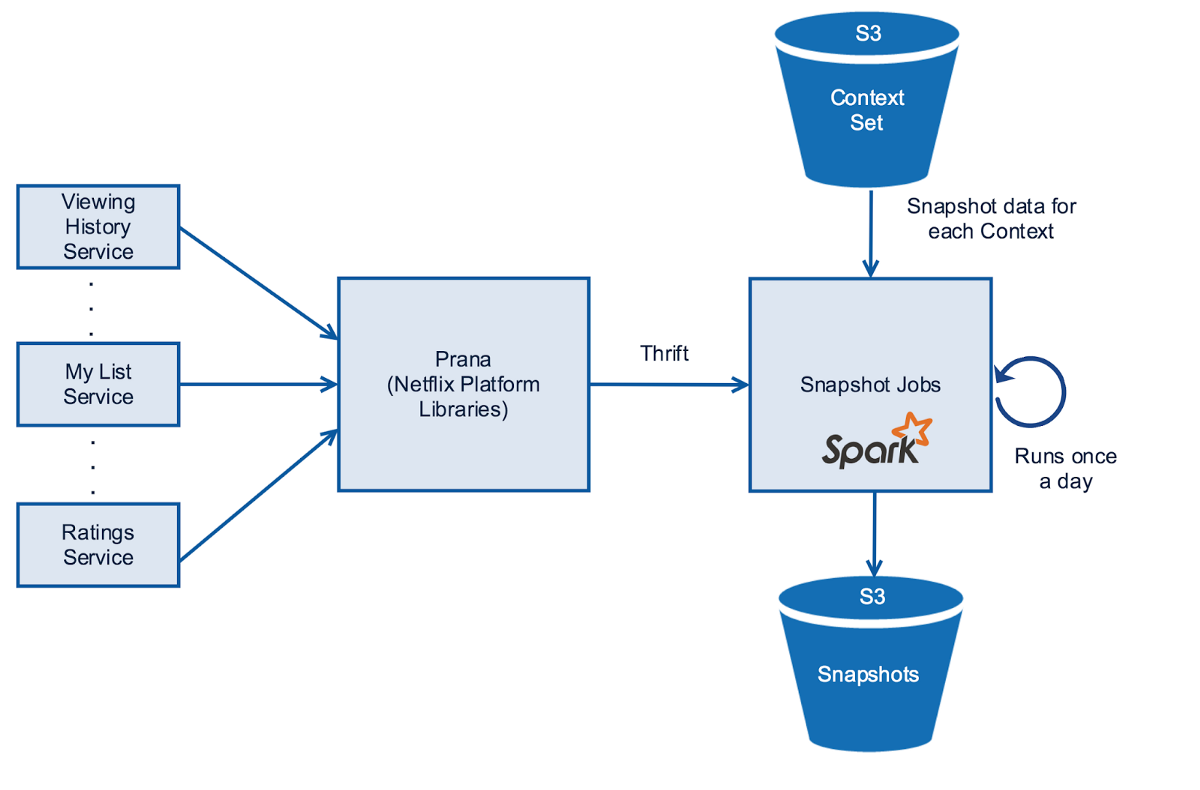
스냅샷들의 데이터 퀄리티를 보장하는 것은 모델 평가를 위해 아주 중요합니다. 그러므로 각각의 스냅샷 서비스의 신뢰도를 저장하여 실험에 이용할 수 있도록 합니다. 신뢰도는 타임아웃 등에서 발생한 Fallback을 제외한 성공적인 데이터 가져오기의 퍼센티지 입니다.
마지막으로 위에서 나온 Spark jobs들을 스케쥴링 해야 합니다. 그래서 넷플릭스는 범용 워크플로우 오케스트레이션, 스케줄링 프레임워크인 Meson을 만들었습니다. Meson은 머신러닝 파이프라인에 최적화되어 있습니다.
시간 여행을 위한 API
마지막으로 특정 시점의 스냅샷 데이터를 S3로부터 가져오는 API입니다.

API는 저장된 S3에 저장된 스냅샷의 경로를 Cassandra에서 가져옵니다. A/B 테스트 식별자가 주어지면 API는 선택된 A/B 테스트 컨텍스트만을 선별하여 필터링합니다. 시스템은 스냅샷을 다시 자바 오브젝트로 변환하고 피쳐 인코더가 오프라인과 온라인에서 완전히 같은 POJOs를 사용할 수 있도록 합니다.
아래의 다이어그램은 전체적인 아키텍처와 스파크가 어디에 사용되었는지를 보여줍니다.
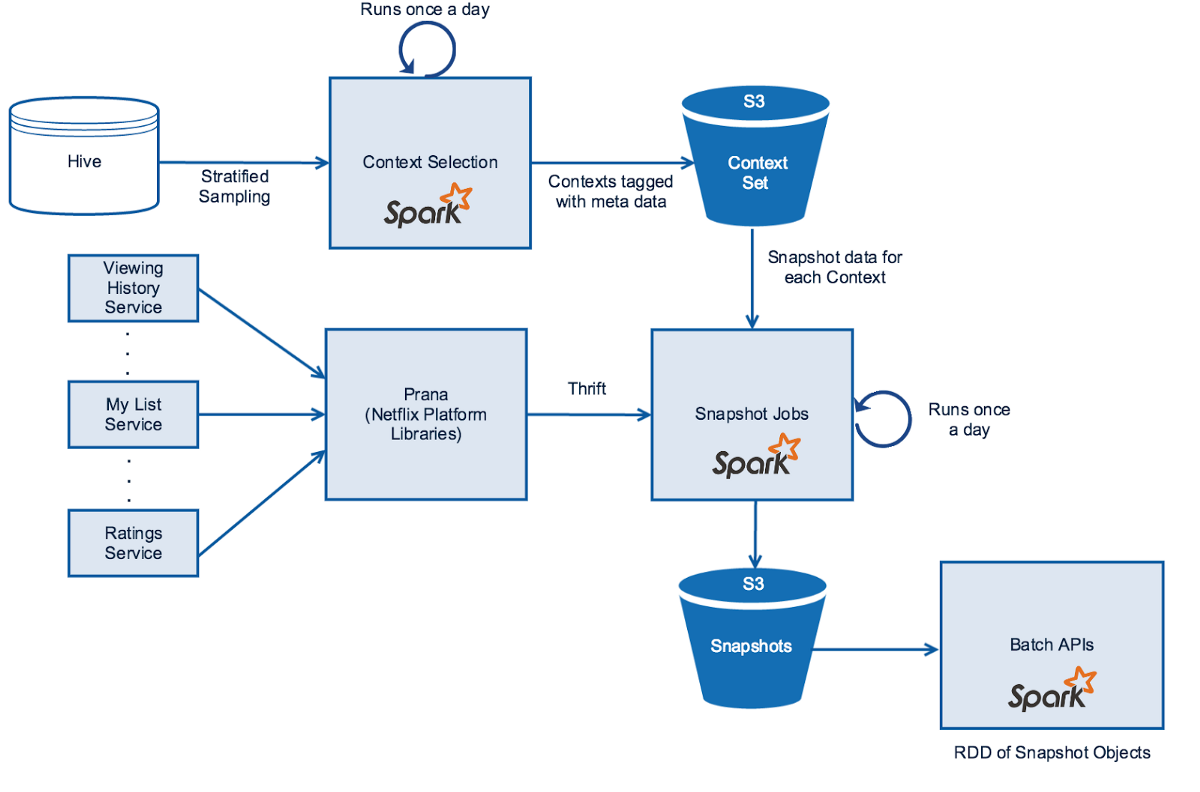
DeLorean: 시간 여행을 통한 피쳐 생성
DeLorean은 실험 계획, 스냅샷 데이터 수집, 과거의 피쳐와 레이블 데이터 셋을 생성하는 내부 프로젝트입니다.
실험 실행
DeLorean은 타임머신을 실행하는 방법, 어떠한 시간 좌표가 필요한지, 어떠한 데이터를 받을지, 결과의 구성을 자동으로 결정함으로써 리서처가 다양한 실험을 실행할 수 있도록 합니다. 리서처는 아래의 내용만을 결정하면 됩니다.
- 레이블 데이터: 관련된 시간 좌표, 아이템들, 각각의 레이블과 연관된 컨텍스트 집합을 얻기 위한 청사진. 이것들은 일반적으로 Hive, Pig, Spark SQL Query를 통해 생성됩니다.
- 필요한 피쳐 인코더 구성을 포함하는 피쳐 모델
- 기존 라이브러리에 존재하지 않는 새로운 피쳐 인코더의 구현
DeLorean은 실험 중에 새 피쳐 인코더를 쓰고 수정할 수 있도록 합니다. 예를 들면, Zeppelin Notebook이나 Spark Shell을 통해서입니다. 그리고 이러한 것들을 피쳐 생성을 위해 즉각적으로 실행할 수 있고 만약 새로운 피쳐 인코더가 쓸만하다고 판단되면 라이브러리에 추가합니다.
피쳐 생성을 위한 고수준의 프로세스는 아래의 다이어그램에 설명되어 있습니다. 연두색 부분은 새로운 실험을 위해 커스터마이징 해야 하는 부분입니다. 이 시나리오를 통해 실험은 기존 피쳐 인코더와 함께 사용하는 새로운 피쳐 인코더를 구현할 수도 있습니다.
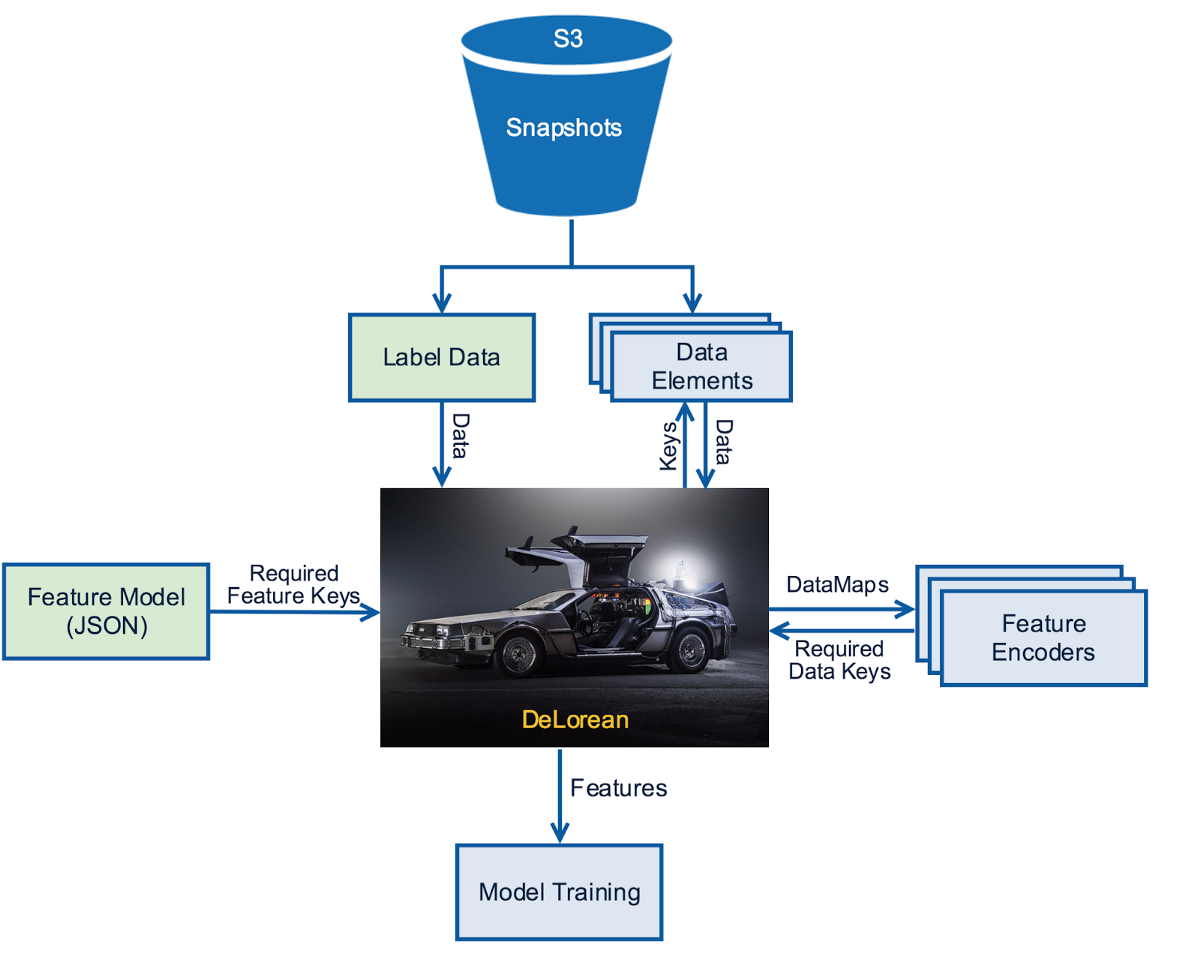
레이블 데이터와 피쳐 인코더
DeLorean에 가장 중요한 입력 중 하나는 1) 컨텍스트, 2) 아이템, 3) 생성될 피쳐에 관여한 레이블을 위한 정보를 포함하는 레이블 데이터입니다. 1) 컨텍스트는 이름에서 알 수 있듯 모델이 사용될 장소에 대한 설정(멤버 프로필, 국가, 시간, 디바이스 등)을 설명합니다. 2) 아이템은 학습되거나 점수가 매겨지거나 순위가 매겨질 요소(비디오, 로우, 검색항목 등)들 입니다. 3) 레이블은 각각의 컨텍스트-아이템 조합의 지도학습에 사용될 타겟들입니다. 개인화 랭킹을 예로 들자면 컨텍스트는 멤버 프로필ID, 국가 코드, 시간 등이고 아이템은 비디오입니다. 마지막으로 레이블은 재생, 비재생이 됩니다. 이 예시에서 레이블 데이터는 실행 로그와 스냅샷화 된 컨텍스트의 집합을 결합함으로써 생성할 수 있습니다.
레이블 데이터셋을 가지고 있으면 원하는 피쳐 인코더들을 사용하여 컨텍스트-아이템 조합에 대해 피쳐를 계산해야 합니다. 각각의 피쳐 인코더는 하나 또는 복수개의 피쳐를 계산하기 위해 컨텍스트와 컨텍스트에 관련된 각각의 타겟 아이템을 POJOs 형식의 row 데이터 엘리먼트와 함께 받습니다.
컨텍스트 변수나, 데이터 엘리먼트 각각의 아이템 타입은 관련된 데이터 키를 가지고 있습니다. 각 피쳐 인코더는 필요로 하는 데이터들의 키 셋을 리턴합니다. DeLorean은 이러한 키들을 데이터 타입 식별에 사용하고 데이터를 받아 데이터 맵의 형태로 돌려줍니다. 데이터 맵은 {데이터 키:데이터 오브젝트}로 구성됩니다.
넷플릭스는 DeLorean을 매 실험에서 다른 타입의 컨텍스트와 아이템의 피쳐 생성 시스템을 커스터마이징 하지 않고 사용할 수 있도록 충분히 유연하게 만들었습니다. DeLorean은 추천뿐만 아니라 Row Ordering 실험에도 사용되었습니다. 또한 쿼리, 프로필, 국가가 컨텍스트로 사용되고 비디오가 아이템이 되는 검색 경험에도 사용되었습니다. 이러한 것들을 위해 DeLorean은 자동으로 레이블 데이터와 데이터 키로부터 피쳐 인코더가 필요로하는 컨텍스트와 아이템의 타입을 추론합니다.
데이터 엘리먼트
데이터 엘리먼트들은 피쳐 인코더에 의해 피쳐로 변형될 재료들입니다. 유저의 시청기록과 같이 컨텍스트와 연관되어 있거나 비디오의 메타데이터같이 모든 컨텍스트에 공유되는 것들입니다. 우리는 이 두가지 타입의 데이터 엘리먼트들을 다른 방식으로 다루고 있습니다.
컨텍스트에 연관된 있는 데이터들을 위해 우리는 위에 묘사된 스냅샷을 이용합니다. 그리고 각자를 데이터 키와 연관시킵니다. 스냅샷 데이터 소스를 각각의 컨텍스트에 대해 값, 아이템, 레이블과 함께 가져오고 하나의 컨텍스트를 하나의 Spark executor로 나누어 보냅니다. 서로 다른 컨텍스트들은 쪼개져서 분산된 피쳐 생성을 활성화합니다. 스냅샷은 (컨텍스트, 데이터 맵)의 RDD 형태로 lazy 로드되며 레이블 데이터와 필수적인 컨텍스트에 연관된 데이터 일련의 결합이 스파크에 의해 실행됩니다.
컨텍스트와 연관되지 않은 데이터들을 위해 DeLorean은 각각의 executor에게 이러한 Bulk 데이터 엘리먼트들을 브로드 캐스트 합니다. 각각의 데이터 엘리먼트들은 사이즈가 크지 않고 업데이트가 느리게 되기 때문에, 이전 버전으로 되돌리기 위한 업데이트 기록을 유지합니다. 이러한 것들은 싱글톤 오브젝트로 메모리에 상주하며 Executor에 의해 처리된 각각의 컨텍스트에 대해 피쳐 생성기가 사용할 수 있도록 합니다. 따라서 컨텍스트 데이터, 컨텍스트에 관련된 스냅샷 데이터 엘리먼트, 그리고 공유된 싱글톤 데이터를 포함하는 완전한 데이터 맵이 생성됩니다.
스파크에 의해 피쳐가 생성되면 그 데이터는 임베딩 된 스키마와 함께 Spark 데이터 프레임으로 나타내어 집니다. 많은 개인화 어플리케이션을 위해 우리는 각각의 컨텍스트를 위해 아이템들의 순위를 매겨야 합니다. 랭킹 프로세스에서 셔플링을 방지하기 위해, 아이템 피쳐들은 결과물에서 컨텍스트별로 그룹화 됩니다. 최종 피쳐들은 Parquet 포맷을 사용하여 Hive에 저장됩니다.
모델 학습, 검증, 테스트
넷플릭스는 타임머신을 통해 생성된 피쳐들을 추천에 사용될 다양한 파트들의 모델 학습에 이용합니다. 피쳐 데이터 프레임을 검증과 테스트하는 학습된 모델을 위한 예측과 지표(Metrics) 계산뿐만 아니라 학습된 피쳐들의 데이터 프레임을 머신러닝 알고리즘에 보내는데 정형화된 스키마를 사용합니다. 또한 모델을 Serialize하는 데에도 정형화된 스키마를 사용하는데, 이 스키마는 추후에 온라인 어플리케이션에 이용되거나 미래의 실험을 위한 모델을 배포하는 데 이용합니다.
아래 그림은 머신러닝 실험이 어떻게 진행하는지에 대해 나타내고 있습니다. 실험이 디자인되면 우리는 컨텍스트, 아이템, 레이블 데이터 셋을 수집합니다. 그다음 데이터 셋을 위한 피쳐를 생성합니다. 모델을 싱글 머신, 멀티 코어, 분산 알고리즘을 이용하여 학습하고 Validation Set의 Metric을 계산하여 파라미터 튜닝을 수행합니다. 그렇게 최선의 모델을 선택하고 눈에 띄는 향상과 결과물이 다르다고 판단되면 다른것을 이용하여 A/B 테스트를 디자인하고 온라인에서 수행합니다. 핵심 지표에서 유의미한 변화를 보여주면, 전체적으로 Roll out 합니다. 그렇지 않다면 나타난 결과에 대해 분석하고 새로운 아이디어에 대해 반복합니다.
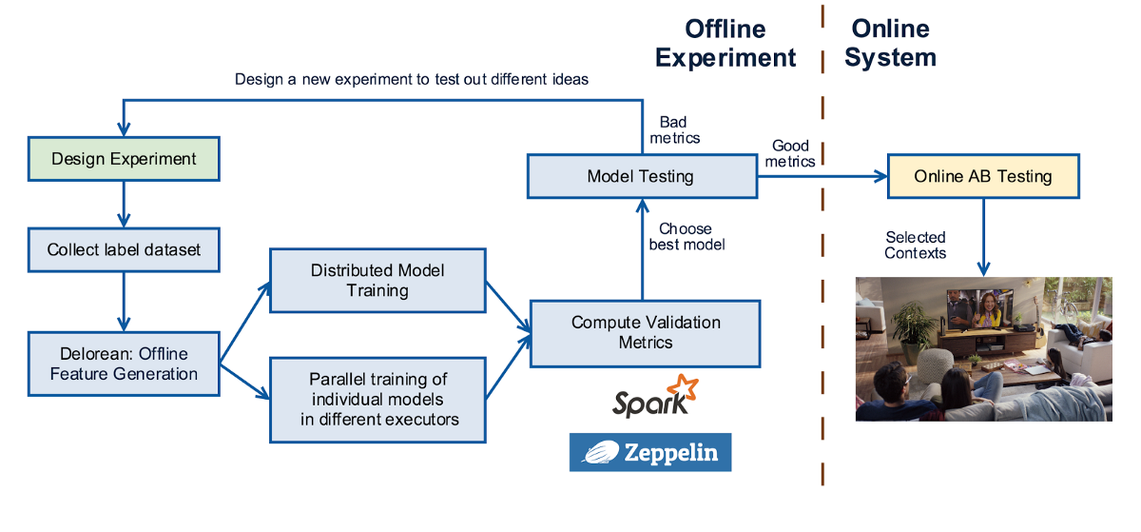
온라인으로 넘어가기
DeLorean을 만든 강한 동기 중 하나는 오프라인 실험과 온라인 점수 시스템에서 같은 피쳐 인코더를 공유하여 모델 학습과 온라인 프로덕션에서 계산되는 생성된 피쳐들 사이의 차이가 없음을 보장하는 것이었습니다. 아이디어가 충분히 온라인에서 테스트할 준비가 되었을 때 모델은 피쳐 설정과 함께 패키징되고 이것은 DeLorean이 피쳐를 생성하기 위해 사용하던 것과 같습니다.
오프라인에서 스냅샷을 통해 수집하는 것과 달리, 프로덕션 시스템에서는 피쳐를 계산하기 위해서 직접적으로 온라인 마이크로서비스들을 호출하여 모델에 사용될 피쳐 인코더들이 필요로하는 모든 데이터 엘리먼트들을 수집합니다. 이것들을 조합하여 데이터 맵으로 나타내고 피쳐 인코더에 넘깁니다. 피쳐 벡터는 추천을 생성하는 예측 계산을 위해 오프라인에서 학습된 모델에게 넘겨집니다. 아래 다이어그램은 오프라인 실험에서 온라인 프로덕션 시스템으로 넘어가는 고수준의 프로세스를 나타냅니다. 노란색은 온라인 시스템이고 파란색은 오프라인 시스템입니다. 피쳐 인코더는 온라인과 오프라인에서 공유되어 피쳐 생성의 일관성을 보장하는 것에 유의하십시오.
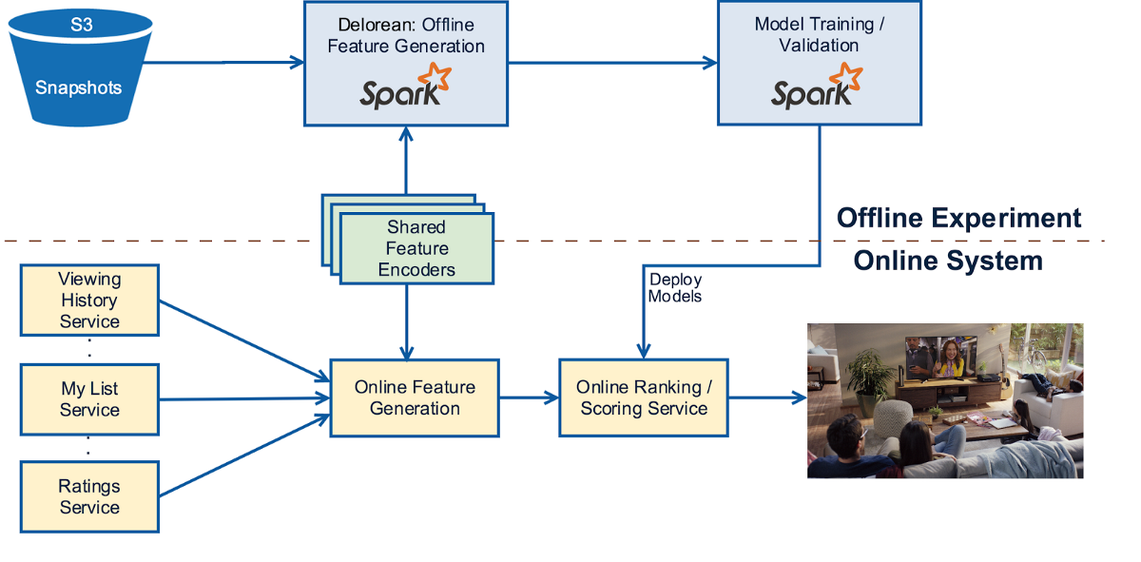
결론 및 Future Work
컨텍스트 셋의 선택을 위해 특정 시점의 온라인 월드의 상태 수집함으로써, 넷플릭스는 과거의 시점으로 돌아갈 수 있는 메커니즘을 만들 수 있었습니다. Spark의 분산되고 Resilient 한 연산력은 우리가 하루에 몇백만 개의 컨텍스트들을 스냅샷화 하고 피쳐 생성, 모델 학습, 검증을 확장성 있게 실행할 수 있게 하였습니다. DeLorean은 추천시스템을 위한 A/B 테스트에서 피쳐 생성을 위해 프로덕션에서 사용되고 있습니다.
이것은 단지 시작일 뿐이고 우리의 접근법을 향상시키기 위한 다양한 방법이 있을 수 있습니다. 주기적으로 배치 스냅샷을 만드는 대신, 우리는 스냅샷을 이벤트로부터 드라이브할 수 있습니다. 예를 들자면 특정 멤버가 우리의 서비스에 방문했을 때입니다. 데이터 수집의 중복을 막기 위해 우리는 또한 전체 스냅샷을 가지고 있기보다 변경 점만을캡쳐할 수도 있습니다. 우리는 또한 새로운 알고리즘 평가나 시스템을 테스트하는데 타임머신 능력을 사용할 계획을 하고 있습니다. 물론 우리는 미래의 일로서 시간을 앞당길 수 있는 능력은 남겨두겠습니다.
빠른 실험은 혁신 문화의 특징입니다. 아이디어를 위한 생산 시간을 줄이는 것은 인프라스트럭처 프로젝트의 성공을 평가하는 핵심 지표입니다. 우리는 회원들을 즐겁게 하고 moments of truth을 얻기 위해 이러한 기반을 계속 구축해 나갈 것입니다.
Author: dbgsprw
Link: https://dbgsprw.github.io/2020/05/12/Distributed Time Travel for Feature Generation/
Copyright: All articles in this blog are licensed under CC BY-NC-SA 3.0 unless stating additionally.